Mobile Gesture-Controlled Speech Synthesis for Performance
This paper was originally presented at the Toronto Electroacoustic Symposium 2008 (7–9 August 2008).
Abstract
We have constructed a wearable gesture-to-speech system for use in music/theatre stage performances as well as in the everyday community. Our system is based on the Glove- TalkII and GRASSP gesture-controlled speech systems but it adds a vizeme-based facesynthesizer. Our portable system is called a Digital Ventriloquized Actor (DIVA) and refines the use of a formant speech synthesizer. Using a DIVA, a user can speak and sing using hand gestures mapped to synthetic sounds and faces.
1. Introduction
The electroacoustic community has invested a great deal of time and effort in the refinement of hardware, synthesis methods, protocols, diffusion systems, and sample playback. Digital imitations of acoustic instruments have become standard for commercial scoring and are finding more acceptance in demos of orchestral works. However, the synthetic human voice remains an instrument that has proven elusive to synthesize, refine and accept. While high quality text-to-speech converters are quite common they lack the musical, sonic and visual expressivity desired for interesting use in performance. Expressive systems such as Cook’s work with (1) and (2) restrict the mobility resulting in the performer being restricted to “speaking” in a specific space or location. To address these deficiencies we have developed a gesture-controlled mobile speech system called a Digital Ventriloquized Actor, or DIVA.
2. Hardware
2.1. Overview
Our system is based on GloveTalkII (3) and GRASSP (4) which are sensor-based systems that allow people to speak using their hands to control a speech synthesizer. DIVAs are the continued development of these systems, with hardware and software refinements and the intriguing addition of a mobile system. The three systems each use a Cyberglove®, a custom TouchGlove and a six degrees of freedom magnetic tracker (Polhemus Fastrak), all controlling a parallel formant speech synthesizer. (5) For mobility the DIVA substitutes a thumb control for the volume foot pedal.

The move to a mobile system also required the addition of a custom-built jacket and harness (Fig. 2) created by the team’s professional designer Hélène Day-Fraser (6), but as far as possible all components are commercially available in order to encourage other performers to assemble their own DIVAs. Granted, the cost of Cybergloves® is quite high, but certainly not as high as some musical instruments.

2.2. Hardware specifics
The Bluetooth Cyberglove® provides measurements of eighteen finger, wrist, and abduction angles, and this data is used to generate liquids, glides, fricatives, affricates and nasals — that is, all the English language consonants except the stops.
The Polhemus Patriot® tracker consists of a belt-mounted 2” cube magnetic field source and a wrist-mounted 0.5” cube receiver, both wired to a control box. The X-Y (front-back-left-right) positional data created by this hardware is used to generate eleven vowel phonemes and the Z (updown) position controls pitch.
The left-handed TouchGlove has two conductive fabric touch pads on the thumb and each of the fingers. By placing the top thumb pad in contact with one of the finger pads a stop consonant such as “B” or “G’, is generated. Connections between the wiring and the conductive material are made using snap fasteners on the back of the glove as suggested in (7).
The left thumb also controls the volume of the synthesizer through the second touch point. When this point contacts a similar touch point on the left side of the jacket, the synthesizer output is turned off. When the contact is broken the output is turned on.
Sound is output through a speaker located on the upper right chest of the user, although the location can be changed if desired. It is also possible to feed the sound to a concert speaker system, although this conflicts with the DIVA ideal of being a self-contained performer.
Figure 3 shows the configuration of the basic hardware components of the DIVA system and the manner in which they communicate.
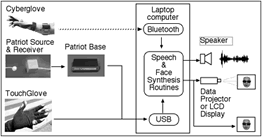
3. Software
DIVAs use formant synthesis for the generation of speech, modeled on the Holmes parallel formant synthesizer. This method generates four formant regions for each of eleven vowels, fifteen consonants, and eight plosives. Noise and voicing components are added as necessary for the consonants and plosives. We have created two software synthesizers, one built completely from Max/MSP objects, and the second refactored from Fortran to C and then compiled as a single Max/MSP object by Keith Hamel. Users are able to select which synthesizer they prefer to use in performance, and a singing voice based on the work of D’Alessandro et al (8) is also available.
To assist in generating accurate data, the DIVA software contains three neural networks which map the right-hand’s positions and gestures to desired vowel and consonant sounds. These networks are normalized Radial Basis Function (RBF) networks (9), “normalized” because they take into account the overshoot that occurs when the user moves the hand outside of or past the trained boundaries. One RBF network maps the X-Y coordinates of the right hand to vowel formants while another one maps right hand finger positions to consonant formants. The third network blends these two formant outputs together based on whether the performer’s hand is configured more closely to a vowel or consonant shape. The centres of each RBF in each network are set to the respond to a hand posture associated with a cardinal sound such as “UU”, “R”, or “SS”. There are 11 cardinal vowel sounds and 15 cardinal consonants mapped this way.
Right hand vertical movement controls pitch through different mappings. This mapping can be continuous, as in the case of speech, or else quantized as in the case of musical scales and modes.
The touch glove triggers preset stop consonant data that are delivered to the formant synthesizer. This preset data interrupts the normal flow of the right hand data for a few milliseconds and then the system switches back to the regular flow of sound generated by the right hand.
All DIVA interface and control methods are written in Max/MSP making it easy for other artists to access the data stream at any point. This means that the data can be used to control other artistic events such as sound diffusion or video processing, or to send data to Phidget or Teleo boards. Currently it is possible to use the glove in a multi-channel environment and move a single sound source around by pointing in the direction of the sound, closing the hand, and “dragging” the sound to a new location before opening the hand.
4. Use
4.1. Training
As with any instrument users must practice with the system in order to master even basic functions. However, the use of neural networks and the normalized RBF functions allows for a faster acquisition of basic skills and intelligibility on the part of the user. A DIVA user must first train the system to recognize specific hand positions or configurations and map them to specific phonemes. To do this, the system is put into a training mode and the user repeatedly places the hand in the desired position and presses the return key on the computer to record data at that timepoint. Six data elements (position and orientation) are recorded from the Polhemus tracker and 18 are collected from the Cyberglove®.
While each user can locate the vowels in whichever space s/he chooses, all users to date have used similar finger angles as well as the same relative vowel positioning shown in Figure 4. This positioning relates to the vowel quadrilateral from the work of (10). An interesting result of each user using the same hand gestures and positions is that it is sometimes possible for observers to recognize what words are being formed by the DIVA user even if the sound is only being passed through headphones. We are, in effect, creating a new sign language that is sonic-based.

Users are able to create many training sessions as they experiment with hand positions and configurations that are most comfortable for them. A training session can consist of all vowels and consonants, a chosen few, or even just one type of vowel. There is no limit to the number of instances of that phoneme that can be included in a training session. Figure 5 shows the interface for the training sessions, with the Dictionary on the left showing the suggested hand configuration, and the list of collected phonemes on the right for the current training session. Users can immediately see the results of the recorded data, and can decide if they wish to keep or delete the record.

4.2. Accents
Once a user has created mapping data for all of the vowels and consonants, they can assemble the best or most appropriate training sessions into an “accent.” Each user develops a personal style of performance as a DIVA, with different sizes of vowel space and slightly different finger configurations, and it is these personal differences that make the term “accent” appropriate. The DIVA system’s ability to quickly and easily remove and replace training data that is deemed to be weak or incorrect results in a considerable improvement in the training time and the training results when compared to the previous GRASSP system.
4.3. Performance
For performance, a DIVA user sets selects the desired accent, sets the vertical boundaries for the pitch control, and selects a voice type, synthesizer, and sound map. If satisfied with this all the parameters can be saved as a Preset, and/or can be set as the default configuration for the user. Different users are able to have a variety of configurations on the same system, or the same user can have different configurations based on the needs of a particular performance.
Launching and setting the performance parameters is done on the performance laptop which is then loaded into the harness. Alternatively, the laptop can be loaded into the harness and then accessed remotely via Apple’s Remote Desktop®. The entire system runs on a closed laptop using Sleepless® software to keep the system from going to sleep when the lid closes.
5. Faces
In vocal performance we are often aware of the contribution of the face. Indeed, the reception of subtly expressive musical passages benefits greatly when the audience is able to see the singer’s face. The DIVA system adds a synthetic face to support such additional expressivity. At present this exists as a simple one-to-one mapping of phoneme-to-vizeme, using the principal component approach by (11). The Max/MSP data stream is connected to the Artisynth Toolkit (12) and the vizemes are controlled through principal component weightings in a manner similar to the generation of phonemes. Figure 6 shows the current face in three different realizations of vizemes.

Currently the face is either projected or shown on a monitor and this negates the mobility of the DIVA, but we expect to add a small chestmounted a small, 5” VGA LCD panel (VertexLCD) to overcome this problem.
6. Current and Future Work
The DIVA system is being tested and modified and users are creating and practicing with their accents. Various issues are being addressed, including design robustness, volume control placement, and ease of donning the garment. We continue improving the glottal excitation waveform. Our librettist Meryn Cadell is creating texts that take advantage of the strengths of the system, and composer Bob Pritchard is developing a new work for DIVA and electroacoustics that will be premiered within a year.
7. Conclusions
Developing synthetic speech that is useful for performance is a difficult yet very attractive goal, and the successful creation of such a system will provide a variety of creators with a powerful tool. This tool will not be confined to merely mimicking human vocal expression, but will extend into other areas of sound synthesis and control, thereby expanding the emotional palette available to users.
The addition of a mobile version expands the range of expression available to the user, in the same manner that is available to performers and creators when we shift from the concert stage to the opera or theatre stage.
8. Acknowledgements
This work has been funded by a SSHRC Research/Creation grant and a New Media Initiative grant from the Canada Council for the Arts and The Natural Sciences and Engineering Research Council of Canada. Support has also been provided by the UBC Media And Graphics Interdisciplinary Centre (MAGIC) and by the UBC Institute for Computing, Information and Cognitive Science (ICICS).
9. References
- Cook, Perry R. and C. Leider. “Squeeze Vox: A New Controller for Vocal Synthesis Models.” International Computer Music Conference (ICMC), 2000.
- Cook, Perry R. “SPASM: a Real-Time Vocal Tract Physical Model Editor/Controller and Singer: The Companion Software Synthesis System.” Computer Music Journal 17/1 (1992), pp. 30–34.
- Fels, Sidney and Geoffrey E. Hinton. “Glove-Talk II: A Neural Network Interface Which Maps Gestures to Parallel Formant Speech Synthesizer Controls.” IEEE Transactions on Neural Networks 9/1 (1998), pp. 205–12.
- Pritchard, Bob and Sidney Fels. “GRASSP: Gesturally Realized Audio, Speech and Song Performance.” Proceedings of NIME 2006, pp. 272–76.
- Rye, J.M. and J.N. Holmes. “A Versatile Software Parallel-Formant Speech Synthesizer.” JSRU Research Report No. 1016 (November 1982).
- Day-Fraser, Hélène, Sidney Fels and Bob Pritchard. “Walk the Walk, Talk the Talk.” International Symposium on Wearable Computing (ISWC) 2008, in press.
- Hartman, Kate. “Conductive Fabric and Thread as Input.” Soft Sensing: ITP Sensor Workshop. http://itp.nyu.edu/physcomp/sensors/Reports/SoftSensing Last accessed 2 August 2009.
- D’Alessandro, Nicolas, Christophe d’Alessandro, Sylvain Le Beux and Boris Doval. “Real-time CALM Synthesizer: New Approaches in Hands-Controlled Voice Synthesis.” Proceedings of NIME 2006, pp. 266–71.
- Fels, Sidney. “Using Normalized RBF Networks to Map Hand Gestures to Speech.” Radial Basis Function Networks 2: New Advances in Design (Studies in Fuzziness and Soft Computing). Edited by Robert J. Howlett and Lakhmi C. Jain. Physica-Verlag, 2001, pp. 59–101.
- Jones, Daniel. English Pronouncing Dictionary. 17th edition. Edited by Peter Roach, James Hartman and Jane Setter. Cambridge: Cambridge University Press, 2006.
- Kuratate, Takaaki, Eric Vatikiotis-Bateson, and Hani Camille Yehia. “Estimation and Animation of Faces using Facial Motion Mapping and a 3D Face Database.” Computer-Graphic Facial Reconstruction. Edited by John G. Clement and Murray K. Marks. Amsterdam: Elsevier Academic Press, 2005, pp. 325–46.
- Fels, Sidney et al. “ArtiSynth: A 3D Biomechanical Simulation Toolkit for Modeling Anatomical Structures.” Journal of the Society for Simulation in Healthcare 2/2 (2007), pp. 148.
Social top